Vanilla RNN’s are overviewed in detail in quite a few works of machine learning literature. However, I find that some of the intricate details to be a lacking. Particularly with what happens with layers surrounding the RNN layer. Furthermore when I first started I had questions like :
Do we need to iterate all layers backprop_interval times?Does every layer need to hold a list of inputs / outputs for each backprop_interval?Do we need backprop_interval number of weights for the RNN layer?Do we need to cache all the state derivatives of the RNN layer?
For this reason we will work through the backprop-through-time equations for an RNN with a prior and post ANN layer and see how we can cache/reuse certain parameters.
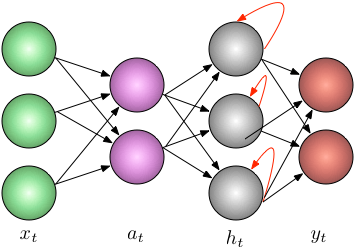
Forward Propagation
It’s always best to start off defining what each variable means and assume a sample sizing.
This ensures that we get our dimensions right along the way.
| Variable Definition | Assumed Sizing |
|---|---|
| : input at time t | [128 x 10] |
| : activation at time t | [128 x 20] |
| : rnn output at time t | [128 x 5] |
| : Weights for , RNN and | [10 x 20] , [20 x 5], [5 x 100] |
| : Recurrent weights at time t | [5 x 5] |
| : Biases for , RNN and | [20], [5], [100] |
| : Activation of first, second and third layers | [128 x 20], [128 x 5], [128 x 100] |
| : Derivative of the activation of first, second and third layers | [128 x 20], [128 x 5], [128 x 100] |
| : prediction at time t | [128, 100] |
We leave the loss to be arbitrary for generalization purposes. An example loss could be an L2 loss for regression or perhaps a cross-entropy loss for classification. We leave the sizing in transpose-weight notation because it keeps logic consistent with data being in the shape of [batch_size, feature]
Backpropagation Through Time
The chain rule for the final ANN [i.e. the emitter of ]:
Note that is merely the loss derivative. For an L2 loss this is just .
We then pass the following back to the previous RNN layer:
The chain rule for the RNN:
A key point that makes the RNN different from a standard ANN is that the derivative of the hidden state is sent backwards through time and compounded through a simple addition operation. More formally this means:
This value is sent backwards through time from the final BPTT time step ( below) until till time t=0. In computation terms this means that needs to be cached and added to itself. Listed below is an example of two time steps of accumulation of the hidden state:
This process is repeated up till the last unroll after which the hidden state’s derivative accumulator is zero’d out (you can also do this when you zero out the gradients in the optimizer).
As shown above we have that all the parameters of the RNN depend on and that is defined as:
An insight here is that the parameters are shared across time; we don’t in fact use different parameters for the RNN, but merely share and jointly update them using BPTT. So with this little tidbit of knowledge we can rewrite our equation from above as such :
This leaves us with the following unsatisfied requirement: which is the activated response from the first ANN. Before we sort out the logistics of the entire BPTT algorithm let’s just write out the equations for the first layer.
The RNN layer will emit which will be used to update the parameters of the first ANN.
The chain rule for the first ANN [i.e. the emitter of ]:
Sizing Verification:
Before we move on let’s just verify that the size of the following are the same.
This is left as an exercise to the reader.
| Variable Name | Desired Size |
|---|---|
| : derivative of ’s weight matrix | [5 x 100] |
| : derivative of ’s bias vector | [100] |
| : derivative of RNN input-to-hidden weight matrix | [20 x 5] |
| : derivative of the RNN’s recurrent weight matrix | [5 x 5] |
| : derivative of the RNN’s bias vector | [5] |
| : derivative of ’s weight matrix | [10 x 20] |
| : derivative of ’s bias vector | [20] |
| : loss delta | [128 x 100] |
| : delta from to RNN | [128 x 5] |
| : delta from RNN to | [128 x 20] |
Step-by-step Forward / Backward Procedure:
Let’s think about this from another way: let’s start by writing the above equations from .
In the example below we will walk through three time steps [i.e our BPTT interval is 3]:
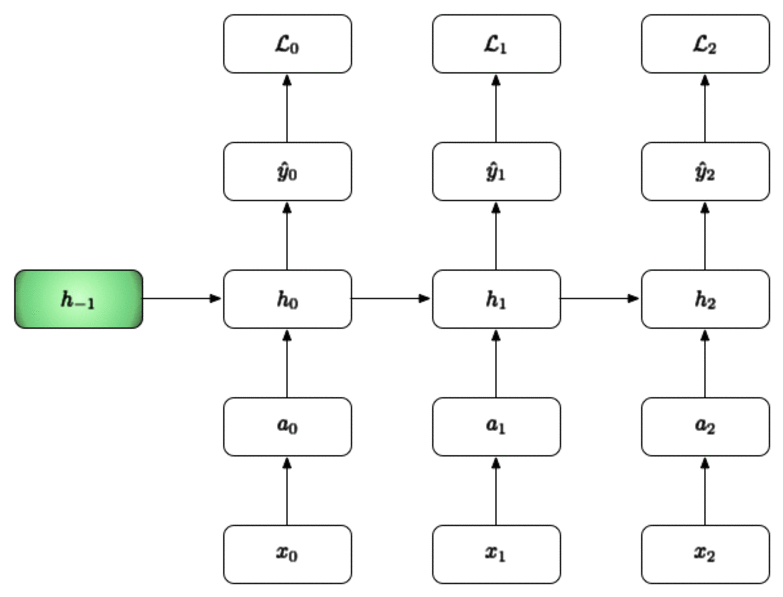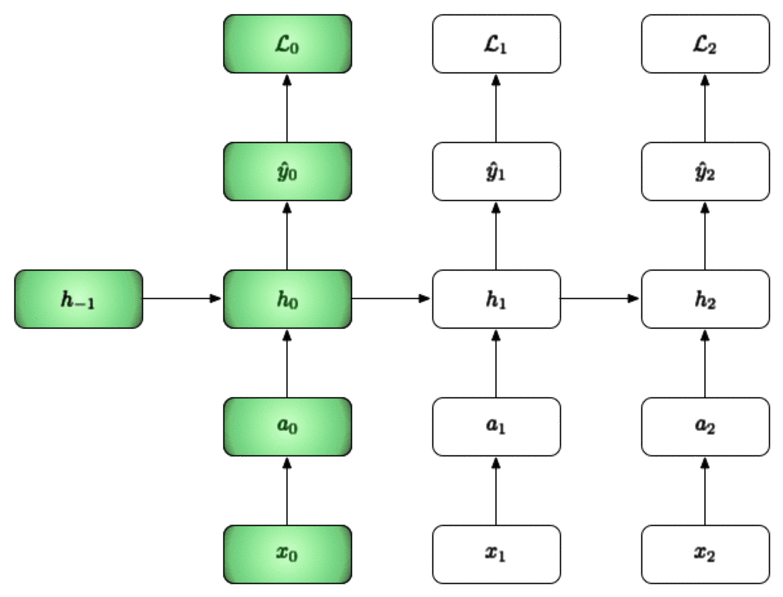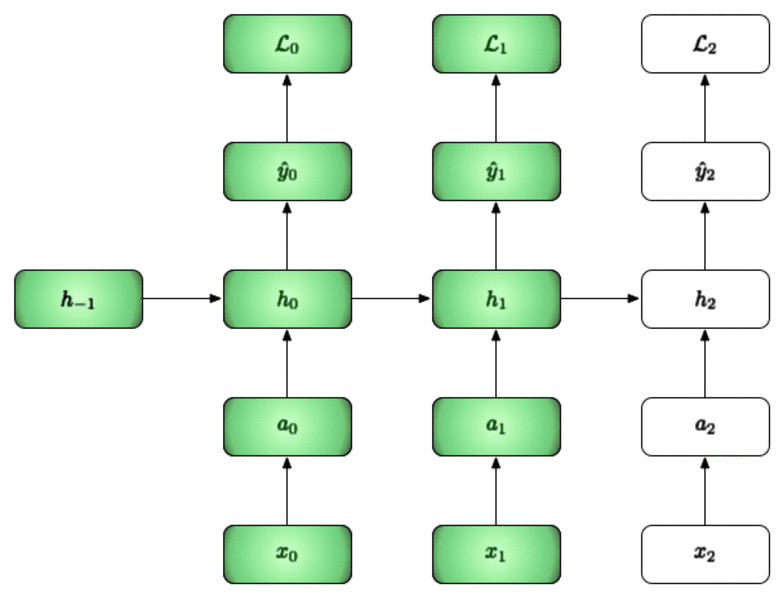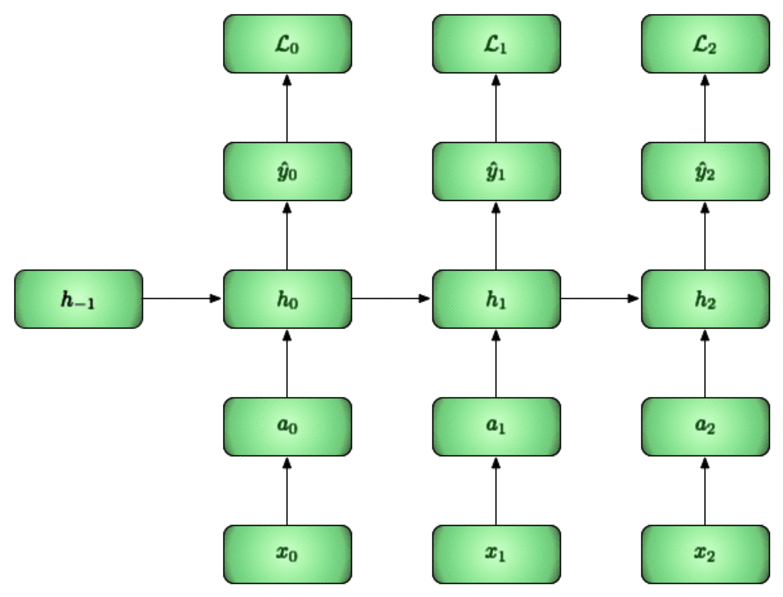
- We start off by initializing the first hidden layer to be zero since we have no data up to this point.
- We can then use and the new to calculate , , and finally
- We repeat this (i.e. we pass the h from the current time to the next time step) and do this for the BPTT interval.
It is good to note here that each of these are vectors. While the loss in the end is reduced via a sum / mean to a single number, for the purposes of backpropagation it is still a vector (eg: ).
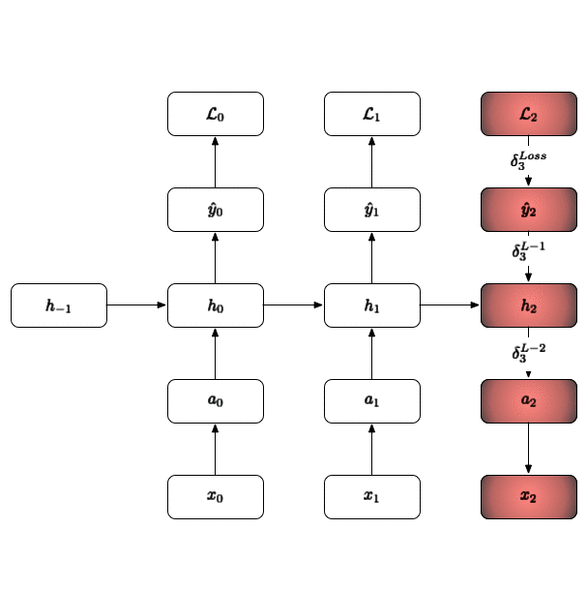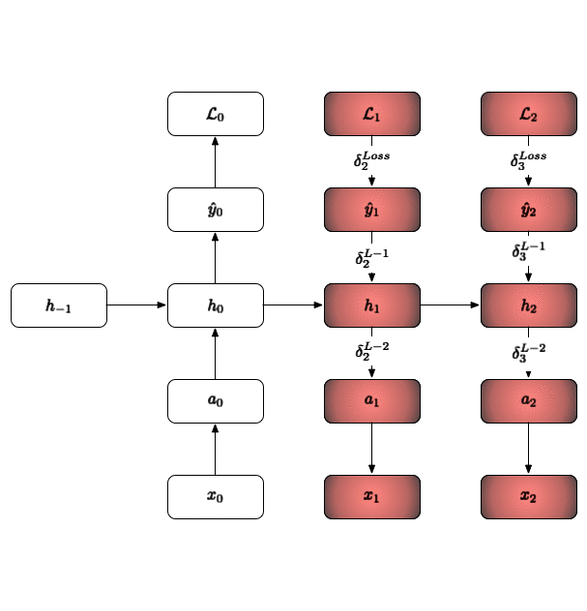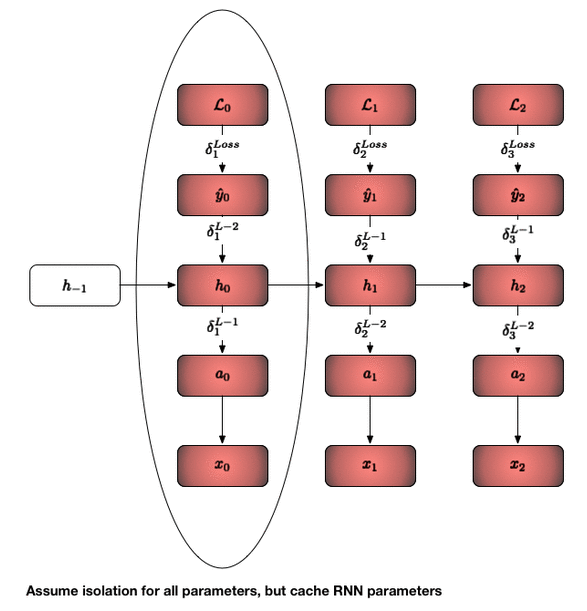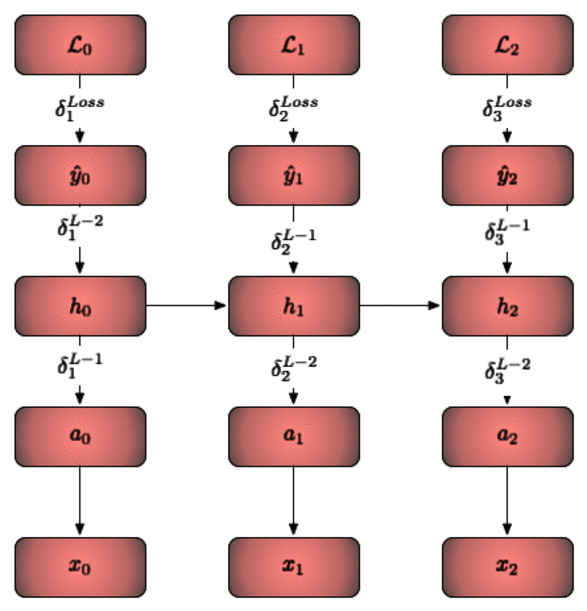
The backward pass is shown above. The key here is that you just update one time slice at a time in the same way you would in a classical neural network. So to revisit the questions posed earlier:
Do we need to iterate all layers backprop_interval times?Yes, you need to get all the loss vectors for the corresponding input minibatches (at each timestep).Does every layer need to hold a list of inputs / outputs for each backprop_interval?Yes. SGD updates are only done after backprop_interval forward pass operations. Since this is the case each layer will need to hold the input / output mapping for each one of those forward passes. This is what makes an RNN trained with backprop-through-time memory intensive as the memory scales with the length of the BPTT interval.Do we need backprop_interval number of weights for the RNN layer?No! They are shared weights/biases between all the recurrent layers and they are updated in one fail swoop!Do we need to cache all the state derivatives of the RNN layer?No! Since they are compounded via a simple addition operator you merely need to keep one value and recursively add to it.
Issues
If you find any errors with any of the math or logic here please leave a comment below.
comments powered by Disqus